Hallucinated references (or HalluCitations) have become a serious anxiety for editors, who are increasingly asking their publishers for products like Signals to help them identify these muddled and made-up references. Some publishers are looking further ahead and asking me, how long will this actually be a problem? Is it even a problem today? Surely the frontier models don’t hallucinate references anymore?
We put it to the test, which turned into a longer journey than I anticipated.
I downloaded a recent publication (doi.org/10.1038/s41598-025-97192-z) and used Claude to remove the existing reference numbers and footnotes from the text.
I then asked Claude Opus 4.7 to reference the text, using this prompt:
“I have written an academic article on “Targeting the proliferation of glioblastoma cells and enhancement of doxorubicin and temozolomide cytotoxicity through inhibition of PFKFB4 and HMOX1 genes with siRNAs” that i plan to submit to the journal scientific reports. I forgot to save references throughout the writing. However, I am confident that it can all be backed up by suitable references. As an expert that understands the literature on the topic and understands how to find appropriate references, please thoroughly reference the attached manuscript. Aim for at least 60 unique references. Ensure that all references have DOIs in them.”
Claude, outsmarting me, was pleased to notice that it was the content of an already published article, and said it would just use the original references.

Because I’d asked for the references to contain DOIs, Claude started trying to find the DOI for each reference using web search. Then, it caught itself and stopped. It asked if this is what I wanted it to do, or if it should find new references. I asked for new references.
After a little while, the reference list was complete! But I ran out of tokens before I could get a PDF. Three hours and a trip to the ice cream shop with my daughter later, the PDF with its 72 new references was ready to be analysed by Signals.

The result: 8 (11%) invalid references. They appeared in all the different forms:
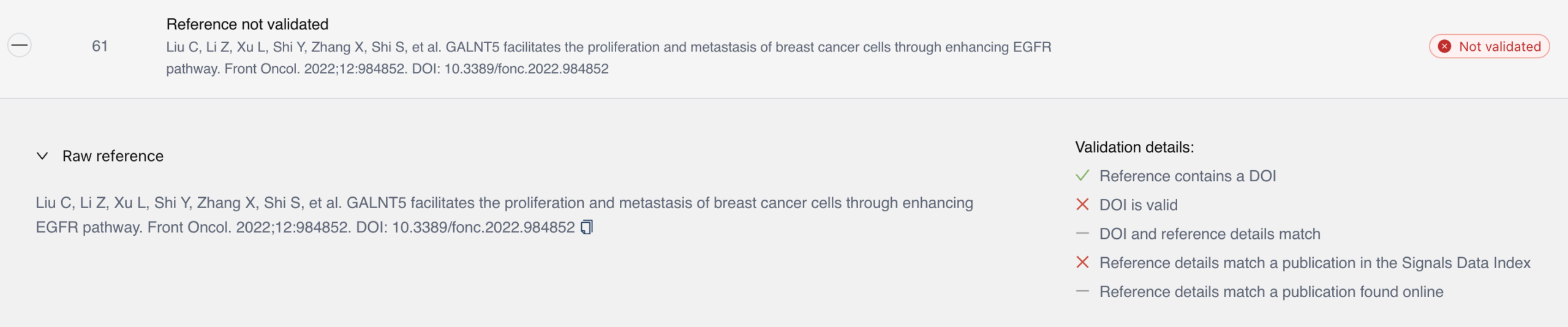
- 2 x Made-up DOIs
- 3 x Mismatch between the title and the DOI
- 2 x Hallucinated titles
- 1 x Hallucinated title and hallucinated DOI
An 11% rate of invalid references is a massive headache for an editorial team.
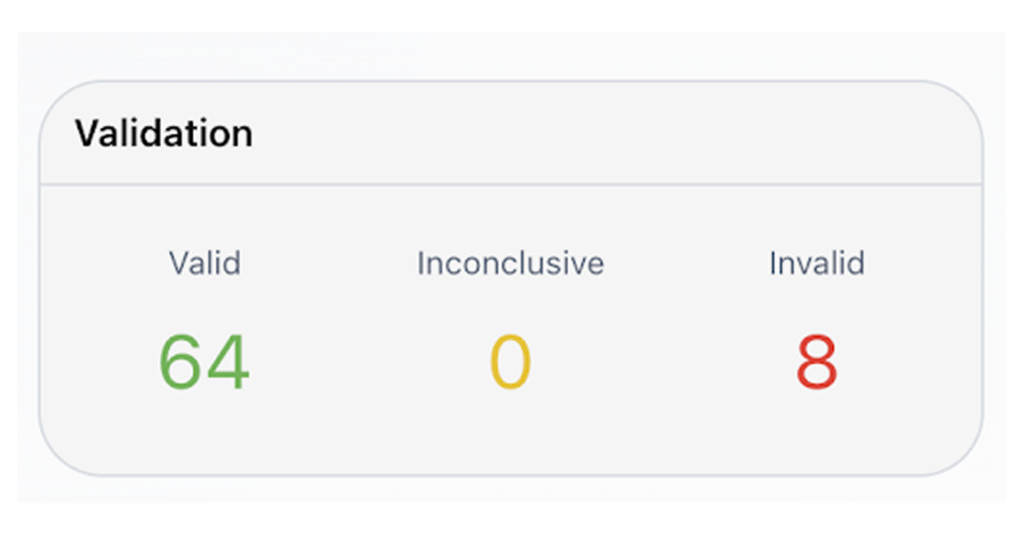
I mentioned this to Ben Kaube (co-founder of Cassyni), who tested the exact same text and prompt with GPT 5.5. It added 87 references with only 1 (2%) invalid reference (Hallucinated DOI).
So what did we learn? The frontier models are still HalluCitating.
While our n=1 experiment indicated that GPT 5.5 may be the better choice for researchers looking for shortcuts, even a low rate of hallucinated references is unacceptable in the scholarly record. Scaled across thousands of submissions, manually identifying these errors becomes a huge time drain for editorial teams.
Get in touch to book a demo of Signals Manuscript Checks to see how we can help your team identify hallucinated references quickly, automatically, and easily within your workflows.
Get in touch
Learn more about Signals and explore how we can support your research integrity strategy. You can:
Email us at hello@research-signals.com
Fill in our demo request form
Following us on LinkedIn